Using the map Wile has found a point where the Road Runner must pass each day, the interesting fact of this point is that is is right after the only stream in the desert, which means that the Road Runner has wet feet when it arrives to the designated point. This is the fact that Wile is going to use - for a frosty trap!
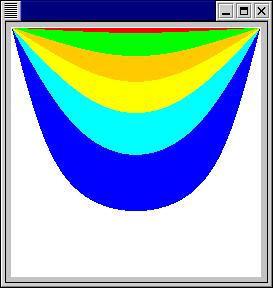
Wile has bought a special cold cube from ACME. This is a metal cube which is cooled to absolute zero (0K) from three (remember that this is a cartoon world - e.g. two dimensional) sides. The idea is to bury the cube in the sand and have the one, uncooled, side sit on the surface. Since the cube is metal the cooling from the three cooled sides will spread to the surface and make the surface very cold, so when the Road Runner places its wet feet on the metal surface it will freeze in place and Wile can easily pick it up and have dinner!
The problem is that while
the three sides are 0K the topside is hit by the sun and the 40C air, thus
the question is will the surface be sufficiently cold that the Road Runner
will in fact get stuck? This requires the surface to be at least -100C.
The stable Freeze-trap
The technique that we use to simulate the temperature development in the cube is called Successive Over-Relaxation, SOR. SOR is a method for solving very large systems of partial differential equations by successive approximations. The general idea is to approximate each element in a matrix to its neighbors until the sum of all changes within a single iteration converges below a given value.
do
{
diff=0.0;
for
i = 1 to n-1
for
j = 1 to n-1 {
temp = A[i,j]
A[i,j] = 0.2 * ( A[i,j] + A[i+1,j] + A[i-1,j] + A[i,j+1] + A[i,j-1] )
diff = diff + abs( A[i,j] temp )
}
} while ( diff>epsilon )
Sequential version of Successive Over-Relaxation
The sequential algorithm is given in Example 1.

Two dimensional finite-differences method for the heat distribution problem
This algorithm may appear hard to parallelize as each calculation depends on two previous results from the same iteration, namely A[i-1, j] and A[i, j-1]. One solution is to implement a diagonal wave-front calculation, but that is not efficient, since the work available is highly unbalanced and frequent communication is required. However, the correctness of the algorithm does not depend on the sequential order reflected in the sequential algorithm. Each point may be updated using results from any iteration. This slows down the convergence slightly, but this is more than compensated by the parallelism gained. Using results from any iteration has the disadvantage that, since this is a successive approximation method, the convergence of the algorithm varies with the number of CPUs, the communication speed, and other parameters. The result is that different configurations will return different, but still correct, results.
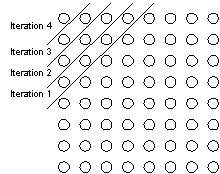
Wave-front approach to parallel two-dimensional finite differences method
Another solution, Red-Black ordering, returns identical results for the same system of equations; independent of the actual computing environment, while at the same time providing sufficient parallelism that real speedup is achieved. With Red-Black ordering, the equation system is divided into alternating red and black points in a checkerboard fashion. Updating a red point depends only on black neighboring points and vice versa. Using this, an algorithm is derived where each worker-process updates all its red points, exchanges the red point values on its borders with the red points from its neighbors. Each worker then updates its black points and repeats the exchange with the black points.
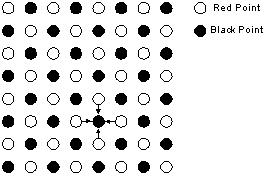
Red-Black checker-pointing for parallel SOR
This problem should be implemented using MPI, to ensure correct results the supplied version should be converted to a Red-Black checker pointing method. The code should be run on from one through 32 nodes (1,2,4,8,16 and 32 will suffice). The Cube should be modeled as a 500x500 grid.
The report should identify
the various choices that has been made as well as individual techniques
that has
been applied to improve
performance. And the impact of each should be documented. In addition the
scalability of your implementation should be discussed and the achieved
performance curve should be discussed.
Any optimization may be applied, if and only if the result is correct and independent of the number of nodes that are used to achieve the solution. Any optimization that is applied must be thoroughly described.